Elasticsearch
ELK Stack의 핵심 구성요소인 Elasticsearch는 텍스트, 숫자, 위치기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터의 검색 및 분석 엔진이다. Apache Lucene을 기반으로 구축되었으며, 간단한 REST API, 거의 실시간(NRT, Near Real Time), 확장성의 이점이 있다.
* Apache Lucene - 자아 언어로 이루어진 정보 검색 라이브러리 오픈소스 소프트웨어
Elasticsearch에 사용되는 용어
- 문서(도큐먼트) - Elasticsearch에서 단일 데이터 단위
- 색인(인덱스) - 문서들을 모아놓은 집합
- 샤드 - 인덱스를 분산하여 저장하는 단위
- 복제본(리플리카) - 복구용으로 사용될 샤드의 복제본
- 노드 - Elasticsearch의 분산 시스템에서 작동하는 하나의 Elasticsearch 서버를 의미한다.
- 마스터 노드 - 클러스터에 구성된 노드 중 하나의 노드는 인덱스의 메타 데이터, 샤드의 위치와 같은 클러스터 상태 정보를 관리하는 마스터 노드의 역할을 수행한다. 마스터 노드의 역할을 수행할 수 있는 노드가 없다면 클러스터는 작동이 정지된다.
- 데이터 노드 - 인덱스된 데이터를 저장하고 있는 노드이다.
- 클러스터 - 하나 이상의 노드가 모인것을 의미한다. 하나의 노드도 하나의 클러스터가 된다.
- 디스커버리 - 노드가 처음 실행 될 때 같은 서버에 설정된 네트워크 상의 다른 노드들을 찾아 하나의 클러스터로 바인딩 하는 과정
Elasticsearch 활용
elasticsearch는
- 앱 및 웹사이트 검색
- 로그 분석
- 앱 성능 모니터링
- 위치 기반 정보 데이터 분석 및 시각화
- 보안 분석
- 비즈니스 분석
등에 사용된다.
Elsticsearch 작동 원리
로그와 같은 다양한 데이터가 logstash, filebeat 등을 통해 Elasticsearch가 다룰 수 있는 데이터로 변환하여 Elasticsearch로 전달된다. Elasticsearch는 이러한 데이터의 인덱스를 생성하고사용자는 이 데이터에 대한 쿼리를 실행하여 Kibana에서 데이터를 시각화 하여 관리할 수 있다.
Elasticsearch 인덱스는 서로 관련되어 있는 문서들의 모음이다. Json 문서로 데이터를 저장하고 각 문서는 키(필드나 속성의 이름)와 그에 해당하는 값을 서로 연결한다.
Elasticsearch에는 역 인덱스라고 하는 데이터 구조를 사용하는데, 이것은 아주 빠른 풀텍스트 검색을 할 수 있도록 설계되었다.
역 인덱스는 문서에 나타나는 모든 고유한 단어의 목록을 만들고, 각 단어가 존재하는 모든 문서를 식별한다.
인덱스 생성 중에 Elasticsearch는 문서를 저장하고 역 인덱스를 구축하여 거의 실시간으로 문서를 검색 가능한 데이터로 만든다.
Elasticsearch 클러스터 구성
Elasticsearch의 노드들은 클라이언트와의 통신을 위한 포트(9200~9299)와 노드 간의 데이터 교환을 위한 (9300~9399) 총 2개의 네트워크 통신을 열어두고 있다.
공식 문서에는 일반적으로 1개의 물리 서버마다 하나의 노드를 실행하는것을 권장한다.
여러 서버에 하나의 클러스터로 실행


물리적인 구성과 상관없이 여러 노드가 하나의 클러스터로 묶이기 위해서는 클러스터명(cluster.name) 설정이 묶여질 노드끼리 모두 동일해야한다. 같은 서버나 네트워크 내부에 있더라도 클러스터명이 동일하지 않으면 논리적으로 서로 다른 클러스터로 실행되고 각각 별개의 시스템으로 인식된다.
하나의 서버에 여러 클러스터로 실행

노드들의 이름(node.name)은 각각 node-1과 node-2, node-3이고 node-1, node-2의 클러스터 명은 es-cluster-1, node-3의 클러스터 명은 es-cluster-2로 구성되었다.
node-1과 node-2는 하나의 클러스터로 묶여있기 때문에 데이터 교환이 일어난다. node-1에 입력된 데이터는 node-2에서도 읽을 수 있고 반대도 가능하다. 하지만 node-3에서는 node-1과 node-2의 입력된 데이터를 읽을 수 없다.
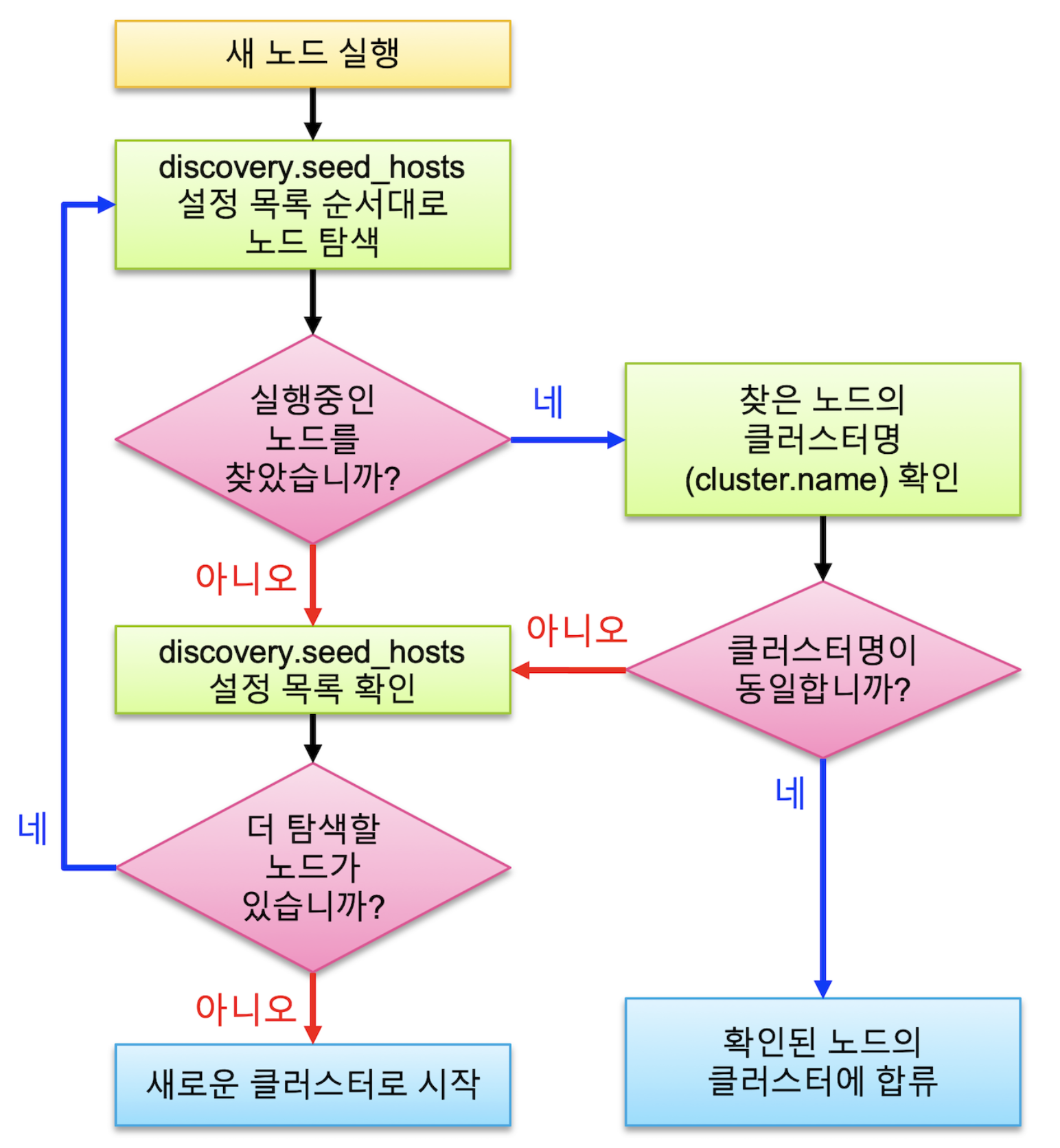
디스커버리
디스커버리란 노드가 처음 실행 될 때 같은 서버에 설정된 네트워크 상의 다른 노드들을 찾아 하나의 클러스터로 바인딩 하는 과정이다.
디스커버리는 다음과 같은 순서로 이루어진다.
- 노드가 존재하는 경우 > cluster.name 확인
- 일치하지 않는 경우 > 1로 돌아가서 다음 주소 확인 반복
- 일치하는 경우 > 같은 클러스터로 바인딩 > 종료
- 노드가 존재하지 않는 경우 > 1로 돌아가서 다음 주소 확인 반복
- 스스로 새로운 클러스터 시작
Elasticsearch를 사용하는 이유
Lucene기반인 Elasticsearch는 속도가 굉장히 빨라 거의 실시간 검색 플랫폼이다. 문서가 인덱스될 때부터 검색 가능해질 때까지의 대기 시가이 아주 짧다.
Elasticsearch에 저장된 문서는 샤드라고 하는 여러 다른 노드에 분산되며, 이 샤드는 복제되어 하드웨어 장애 시 복제된 사본을 제공한다. 이 분산 기능은 굉장히 많은 수의 서버까지 확장가능하고 많은 양의 데이터를 처리할 수 있게 해준다.
Elasticsearch는 많은 기능이 제공된다. 속도, 확장성, 복원력뿐 아니라, 데이터 롤업, 인덱스 수명 주기 관리 등과 같이 데이터를 훨씬 더 효율적으로 저장하고 검색할 수 있게 해주는 기능이 다수 제공되고 있다.
'ELK' 카테고리의 다른 글
| [ELK] SpringBoot Logback 과 ELK Stack 연동 (2) | 2022.12.30 |
|---|---|
| [Curator] Curator를 이용하여 elasticsearch index 관리 (0) | 2021.12.03 |
| [ELK] Filebeat 설치 및 시작 for Mac (Elasticsearch, Kibana 연동) (0) | 2021.11.15 |
| [ELK] Logstash 와 Filebeat의 차이 (0) | 2021.11.15 |



